Zeppelin简介
Apache Zeppelin是一个让交互式数据分析变得可行的基于网页的开源框架。Zeppelin提供了数据捏取、发现、分析、可视化与协作等功能。 Zeppelin 是一个提供交互数据分析且基于Web的笔记本。方便你做出可数据驱动的、可交互且可协作的精美文档,并且支持多种语言,包括 Scala(使用 Apache Spark)、Python(Apache Spark)、SparkSQL、 Hive、 Markdown、Shell等等。
试验环境搭建
跟之前的博文[Spark] 使用Spark2.30读写Hive2.3.3一样,本文的环境继续使用GitHub: martinprobson/vagrant-hadoop-hive-spark通过Vagrant搭建了一个Hadoop 2.7.6 + Hive 2.3.3 + Spark 2.3.0的虚拟机环境。不过当前scripts/common.sh中ZEPPELIN_VERSION=0.7.2,而Zeppelin 0.7.2已不可访问,需要改成最新版0.8.0。 按照GitHub: martinprobson/vagrant-hadoop-hive-spark说明执行zeppelin-daemon.sh start,结果说权限不足,因此我只好兜一圈开启Zeppelin守护进程。
vagrant@node1:~$ zeppelin-daemon.sh start
find: File system loop detected; ‘/home/ubuntu/zeppelin/zeppelin-0.8.0-bin-netinst’ is part of the same file system loop as ‘/home/ubuntu/zeppelin’.
Pid dir doesn't exist, create /home/ubuntu/zeppelin/run
mkdir: cannot create directory ‘/home/ubuntu/zeppelin/run’: Permission denied
/home/ubuntu/zeppelin/bin/zeppelin-daemon.sh: line 187: /home/ubuntu/zeppelin/logs/zeppelin-vagrant-node1.out: Permission denied
/home/ubuntu/zeppelin/bin/zeppelin-daemon.sh: line 189: /home/ubuntu/zeppelin/logs/zeppelin-vagrant-node1.out: Permission denied
/home/ubuntu/zeppelin/bin/zeppelin-daemon.sh: line 196: /home/ubuntu/zeppelin/run/zeppelin-vagrant-node1.pid: No such file or directory
cat: /home/ubuntu/zeppelin/run/zeppelin-vagrant-node1.pid: No such file or directory
Zeppelin process died [FAILED]
vagrant@node1:~$ sudo -sE
root@node1:~# su - ubuntu
To run a command as administrator (user "root"), use "sudo ".
See "man sudo_root" for details.
ubuntu@node1:~$ pwd
/home/ubuntu
ubuntu@node1:~$ ls
zeppelin zeppelin-0.8.0-bin-netinst
ubuntu@node1:~$ zeppelin-daemon.sh start
find: File system loop detected; ‘/home/ubuntu/zeppelin/zeppelin-0.8.0-bin-netinst’ is part of the same file system loop as ‘/home/ubuntu/zeppelin’.
Pid dir doesn't exist, create /home/ubuntu/zeppelin/run
Zeppelin start [ OK ]
Spark引擎分析HDFS文件实验
- 进入Zeppelin UI,点击“Create new note”创建新的笔记,名字叫Spark Sample。
- 将测试文件放到hdfs集群上:
vagrant@node1:~$ wget http://archive.ics.uci.edu/ml/machine-learning-databases/00222/bank.zip vagrant@node1:~$ unzip bank.zip vagrant@node1:~$ rm -rf bank.zip vagrant@node1:~$ hadoop fs -mkdir /test vagrant@node1:~$ hadoop fs -put ./bank*.* hdfs://10.211.55.101/test vagrant@node1:~$ hadoop fs -ls /test SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/usr/local/hadoop-2.7.6/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/usr/local/apache-tez-0.9.1-bin/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory] Found 3 items -rw-r--r-- 1 vagrant supergroup 4610348 2018-07-09 05:24 /test/bank-full.csv -rw-r--r-- 1 vagrant supergroup 3864 2018-07-09 05:24 /test/bank-names.txt -rw-r--r-- 1 vagrant supergroup 461474 2018-07-09 05:24 /test/bank.csv - 执行下列修改过的Zeppelin指南示例代码:
val bankText = sc.textFile("hdfs://10.211.55.101/test/bank-full.csv") case class Bank(age:Integer, job:String, marital : String, education : String, balance : Integer) // split each line, filter out header (starts with "age"), and map it into Bank case class val bank = bankText.map(s=>s.split(";")).filter(s=>s(0)!="\"age\"").map( s=>Bank(s(0).toInt, s(1).replaceAll("\"", ""), s(2).replaceAll("\"", ""), s(3).replaceAll("\"", ""), s(5).replaceAll("\"", "").toInt ) ) // convert to DataFrame and create temporal table bank.toDF().registerTempTable("bank")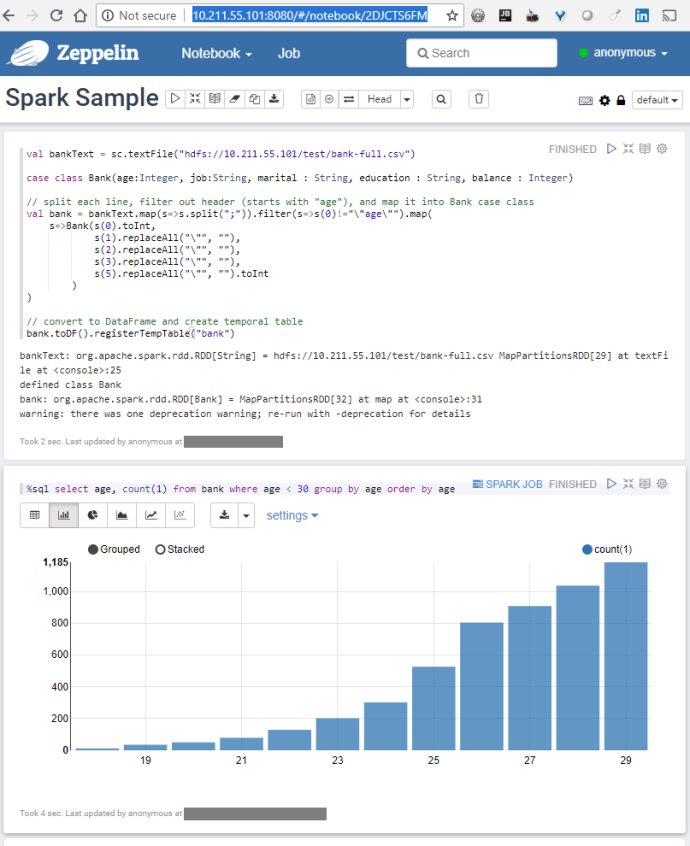 数据分析结果可以以表、条形图、饼图、面积图、曲线图、散点图的形式表现。
数据分析结果可以以表、条形图、饼图、面积图、曲线图、散点图的形式表现。