Spark读取Hbase有以下几张方式:
- Spark的JavaSparkContext.newAPIHadoopRDD / SparkContext.newAPIHadoopRDD方法
- HBase的hbase-spark
- Hortonworks的Spark HBase Connector
- Cloudera labs的SparkOnHBase 本文就Spark自带的方法进行示范和演示。
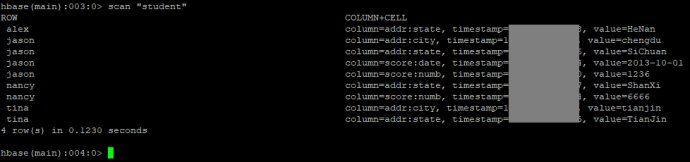
HBase数据库
Spark范例
HelloSparkHBase.java
import org.apache.spark.SparkContext;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
import org.apache.spark.api.java.function.Function;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.mapreduce.TableInputFormat;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.util.Bytes;
import scala.Tuple2;
public class HelloSparkHBase {
public static void main(String[] args) {
try {
Configuration conf = HBaseConfiguration.create();
conf.set(TableInputFormat.INPUT_TABLE, "student");
SparkSession spark = SparkSession
.builder()
.appName("
.config("spark.some.config.option", "some-value")
.getOrCreate();
try (Connection connection = ConnectionFactory.createConnection(conf);
Admin admin = connection.getAdmin()) {
if (admin.tableExists(TableName.valueOf("student"))) {
System.out.println("Table student exist at HBase!");
SparkContext sc = spark.sparkContext();
JavaRDD<Tuple2<ImmutableBytesWritable, Result>> studentPairRDD =
sc.newAPIHadoopRDD(conf,
TableInputFormat.class,
ImmutableBytesWritable.class,
Result.class).to;
JavaRDD<StudentRecord> studentRDD = studentPairRDD.map(
new Function<Tuple2<ImmutableBytesWritable,Result>,
StudentRecord>() {
@Override
public StudentRecord call(
Tuple2<ImmutableBytesWritable, Result> tuple)
throws Exception {
Result result = tuple._2;
String rowKey = Bytes.toString(result.getRow());//row key
String state = Bytes.toString(result.getValue(
Bytes.toBytes("addr"),
Bytes.toBytes("state")));
String city = Bytes.toString(result.getValue(
Bytes.toBytes("addr"),
Bytes.toBytes("city")));
String dt = Bytes.toString(result.getValue(
Bytes.toBytes("score"),
Bytes.toBytes("date")));
String numb = Bytes.toString(result.getValue(
Bytes.toBytes("score"),
Bytes.toBytes("numb")));
StudentRecord record = new StudentRecord(
rowKey, state, city, dt, numb);
return record;
}
});
Dataset<Row> studentDF = spark.createDataFrame(
studentRDD,
StudentRecord.class);
studentDF.show();
}
}
spark.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
StudentRecord.java
import java.io.Serializable;
public class StudentRecord implements Serializable {
private String name;
private String addrState;
private String addrCity;
private String scoreDate;
private String scoreNumb;
public StudentRecord() { }
public StudentRecord(String name,
String addrState,
String addrCity,
String scoreDate,
String scoreNumb) {
this.name = name;
this.addrState = addrState;
this.addrCity = addrCity;
this.scoreDate = scoreDate;
this.scoreNumb = scoreNumb;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getAddrState() {
return addrState;
}
public void setAddrState(String addrState) {
this.addrState = addrState;
}
public String getAddrCity() {
return addrCity;
}
public void setAddrCity(String addrCity) {
this.addrCity = addrCity;
}
public String getScoreDate() {
return scoreDate;
}
public void setScoreDate(String scoreDate) {
this.scoreDate = scoreDate;
}
public String getScoreNumb() {
return scoreNumb;
}
public void setScoreNumb(String scoreNumb) {
this.scoreNumb = scoreNumb;
}
@Override
public String toString() {
return "StudentRecord{" +
"name='" + name + '\'' +
", addrState='" + addrState + '\'' +
", addrCity='" + addrCity + '\'' +
", scoreDate='" + scoreDate + '\'' +
", scoreNumb='" + scoreNumb + '\'' +
'}';
}
}
run.sh
#!/bin/bash
HADOOP_HOME=/usr/local/hadoop
HBASE_HOME=/usr/local/hbase
SPARK_HOME=/usr/local/spark
CLASSPATH=.:$HBASE_HOME/conf:$(hbase classpath):/usr/local/spark/jars/*
rm -rf *.jar
rm -rf *.class
javac -cp $CLASSPATH HelloSparkHBase.java
jar cvfe hello-spark-hbase.jar HelloSparkHBase *.class
spark-submit --class HelloSparkHBase --deploy-mode client --master local[2] --conf spark.executor.extraLibraryPath=$(hbase classpath) --jars $(echo /usr/local/hbase/lib/*.jar | tr ' ' ',') ./hello-spark-hbase.jar
spark-submit的–jars选项仅接受逗号分隔的jar文件,不接受目录扩展。
测试
hadoop@node50064:~/sparkhbasetest$./run.sh
......
Table student exist at HBase!
......
+--------+---------+-----+----------+---------+
|addrCity|addrState| name| scoreDate|scoreNumb|
+--------+---------+-----+----------+---------+
| null| HeNan| alex| null| null|
| chengdu| SiChuan|jason|2013-10-01| 1236|
| null| ShanXi|nancy| null| 6666|
| tianjin| TianJin| tina| null| null|
+--------+---------+-----+----------+---------+
......
参考
Spark SQL, DataFrames and Datasets Guide
StackOverflow: How to read from hbase using spark
Reading Data from HBase table using Spark
StackOverflow: Spark spark-submit –jars arguments wants comma list, how to declare a directory of jars?
Use Spark to read and write HBase data
Spark On Hbase Read (
Setting Up a Sample Application in HBase, Spark, and HDFS
Spark与HBase的整合
Spark读写Hbase的二种方式对比
Spark实战之读写HBase