想用一下python的xpath功能分析一个html文件,lxml是比较不错的xml/html解析库,lxml功能强大,性能也不错,此外也包含了ElementTree,html5lib ,beautfulsoup 等库。 可惜我的html文件格式不是很严谨,lxml的ElementTree处理不了,就转而想用lxml的beautfulsoup来处理。 结果lxml找不到BeautifulSoup库。
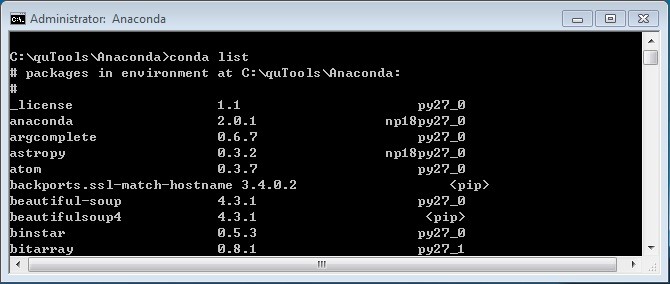
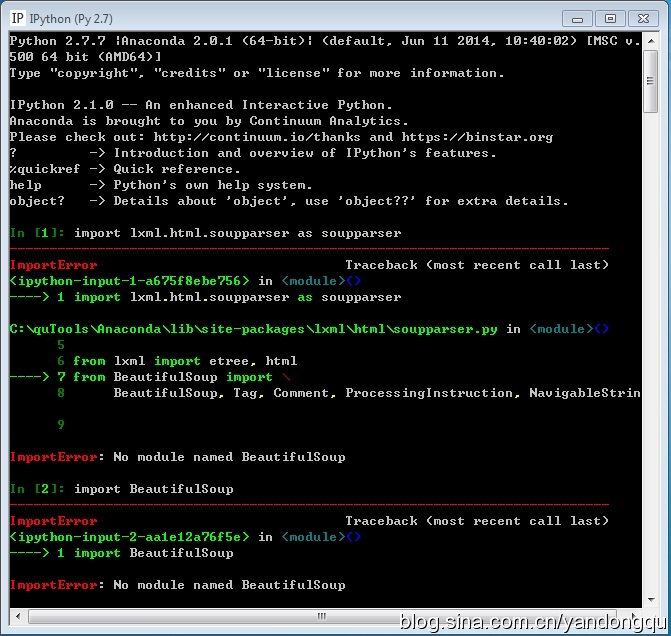 查了一下Anaconda装的库里面明明有Beautiful Soup 4.3.1,感觉很奇怪!!
lxml.html.soupparser引入BeautifulSoup 4的work-around
原来Beautiful Soup 3目前已经停止开发,Beautiful Soup 4移植到了BS4。
查了一下Anaconda装的库里面明明有Beautiful Soup 4.3.1,感觉很奇怪!!
lxml.html.soupparser引入BeautifulSoup 4的work-around
原来Beautiful Soup 3目前已经停止开发,Beautiful Soup 4移植到了BS4。
{kind=link}
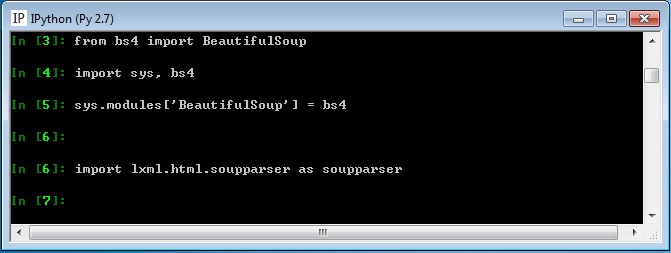
下面的语句就可以引入Beautiful Soup 4了,可是lxml还是无法引入beautfulsoup。
from bs4 import BeautifulSoup
stackoverflow有一个帖子import error due to bs4 vs BeautifulSoup讲了一个work-around,可以欺骗lxml从而引入beautfulsoup。测试一下,果然工作正常了。
import sys, bs4
sys.modules['BeautifulSoup'] = bs4
import lxml.html.soupparser as soupparser