ImportTsv简介
ImportTsv是一款用于将TSV格式数据导入HBase的工具。它有两种用法:
- 通过Put将TSV格式数据导入HBase
- 通过批量导入数据的方式生成用于加载进HBase的存储文件
下面看一下ImportTsv的使用说明:
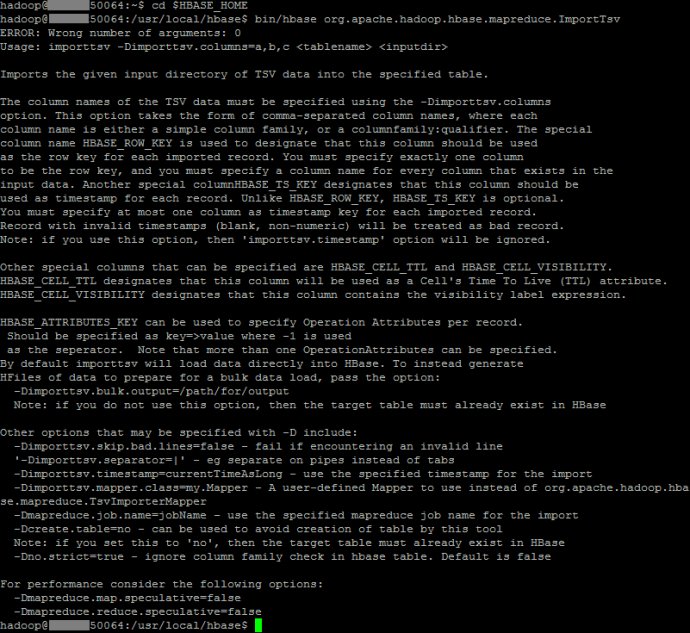
ImportTsv参数
-Dimporttsv.skip.bad.lines=false - 若遇到无效行则失败 ‘-Dimporttsv.separator=|’ - 使用特定分隔符| -Dimporttsv.timestamp=currentTimeAsLong - 使用导入时的时间戳 -Dimporttsv.mapper.class=my.Mapper -使用用户自定义Mapper类替换TsvImporterMapper -Dmapreduce.job.name=jobName - 对导入使用特定mapreduce作业名 -Dcreate.table=no - 避免创建表,注:如设为为no,目标表必须存在于HBase中 -Dno.strict=true - 忽略HBase表列族检查。默认为false
ImportTsv测试
准备数据
hadoop@node50064:~$ hadoop fs -cat /user/hadoop/tsv_input/sales2013.csv
Name,Sex,Age,Height,Weight
Alfred,M,14,69,112.5
Alice,F,13,56.5,84
Barbara,F,13,65.3,98
Carol,F,14,62.8,102.5
Henry,M,14,63.5,102.5
James,M,12,57.3,83
Jane,F,12,59.8,84.5
Janet,F,15,62.5,112.5
Jeffrey,M,13,62.5,84
John,M,12,59,99.5
Joyce,F,11,51.3,50.5
Judy,F,14,64.3,90
Louise,F,12,56.3,77
Mary,F,15,66.5,112
Philip,M,16,72,150
Robert,M,12,64.8,128
Ronald,M,15,67,133
Thomas,M,11,57.5,85
William,M,15,66.5,112
准备目标表
hbase(main):001:0> create 'sales2013', 'info'
0 row(s) in 4.5730 seconds
=> Hbase::Table - sales2013
hbase(main):002:0> create 'sales2013bulk', 'info'
0 row(s) in 2.2790 seconds
=> Hbase::Table - sales2013bulk
通过Put方式导入到HBase表sales2013
bin/hbase org.apache.hadoop.hbase.mapreduce.ImportTsv '-Dimporttsv.separator=,' -Dimporttsv.columns='HBASE_ROW_KEY,info:Sex,info:Age,info:Height,info:Weight' sales2013 /user/hadoop/tsv_input
通过批量导入方式导入到HBase表sales2013bulk
bin/hbase org.apache.hadoop.hbase.mapreduce.ImportTsv '-Dimporttsv.separator=,' -Dimporttsv.columns='HBASE_ROW_KEY,info:Sex,info:Age,info:Height,info:Weight' -Dimporttsv.bulk.output=/user/hadoop/tsv_output sales2013bulk /user/hadoop/tsv_input
# completebulkload工具用于将生成的存储文件移入一个HBase表
bin/hbase org.apache.hadoop.hbase.mapreduce.LoadIncrementalHFiles /user/hadoop/tsv_output sales2013bulk
ImportTsv相关源码
ImportTsv.java
TsvImporterMapper.java
LoadIncrementalHFiles.java